

GPU(Graphics Processing Unit)的概念早在2000年前的時候就有了,但是都是以獨立的運算晶片存在,早期的顯示卡3D與2D顯示的處理晶片是拆開的。在2006年以前,Nvidia的Geforce與ATI的Radeon時代,就將2D與3D的運算整合至單一繪圖晶片的核心裡,並將核心分為兩大部分頂點著色器(Vertex Shader)與像素著色器(Pixel Shader),但是,顯示卡的GPU在電腦所扮演的角色就是做為處理”顯示”的工作,雖然可以做顯示幾何的向量或矩陣運算,所有大量運算像是物理運算、數值運算,除了CPU,無第二個可以分擔處理的部分。在早期的動畫或特效製作,如果要加速製作速度,好像只能增加CPU的速度與數量。早期的GPU運算,沒有統一的介面在2008年後Geforce 9系列推出了CUDA的GPU可程式化SDK介面之後,便開啟了GPU運算的一扇便利的大門。
CPU能夠處理資料速度,決定在頻率與核心的電晶體數量,CPU的多核心化也是因為晶片製程縮小之後所能夠達到的,但是因為CPU要處理的控制類型與運算資料複雜度,也讓CPU本身設計架構無法像GPU般的精簡,加上電腦節能的需求,在追求頻率的處理速度上也只能達到一定的平衡點之下,現今的CPU也只能從增加處理核心的數量來提升處理速度。
GPU走的路則完全是不一樣的路,GPU的運算單元是相當精簡的架構,因此可以在晶片一定的面積裡塞入許多運算的單元。最早的GPU基本上為的是能同時處理多個vertex shader與pixel shader的顯示流程為主,後來統一使用以多個運算單元的核心來負責分散處理這些顯示的流程,在Geforce 8xxx系列的GPU就開始支援了CUDA的規格,透過CUDA的SDK來編譯可以在GPU上執行的程式碼。
早期的CUDA功能規格限制在GPU的硬體能力,所以使用CUDA寫程式必須依照GPU Device的限制來寫,最早包含暫存器的大小,一次能載入多少的變數,執行多少次迴圈都有限制,隨著硬體的能力提升,與支援CUDA SDK版本的改進,這些限制也慢慢的不存在了。也從這邊就可以看出來,GPU的硬體是特化過後的產品,每個核心都有一個浮點乘法加法單元,專為做顯示或運算而生,所以不像CPU需要做更複雜的事情,自然可以在一顆晶片裡製作出相當多的運算核心,現今的最強大的GPU Kepler GK110 核心數約為2880個,做到使用Kepler GK210雙GPU晶片的版本可以達到4992個,Geforce的GTX TITAN Z雙GPU版本則有5760個核心。

Geforce的GTX TITAN Z雙GPU版本則有5760個核心
GPU的運算最大瓶頸就是記憶體,包含顯示的部分,現在的顯示卡的記憶體大小動輒1GB起跳,顯示真的有需要這麼大的記憶體嗎,如果顯示需要用到”運算”之後才畫在畫面上,顯示卡上的記憶體就是用來暫存這些資料準備給運算用的,或是運算完成後給顯示使用的繪製資料,用來顯示到螢幕的使用的暫存記憶體反而很少。而GPU只能存取顯卡上的記憶體,無法存取系統的記憶體,也就是說,所有需要運算的資料,都必須從系統複製一份到GPU內建的記憶體,運算完成再傳回系統記憶體,這一來一往就耗費了許多存取資料的時間,而且PCI匯流排的速度就影響很大。當運算的資料多過於GPU上的記憶體量時,就要拆出好幾個循環來運算,效率就會更低。
動畫產業的流程基本上就是Modeling(建模)->Surfacing(材質設定)->Rigging(骨架設定)->Layout(構圖)->Animation(動畫)->rendering(算圖),GPU能介入的第一個環節就是顯示的效率,讓大量的幾合元件快速的在螢幕上繪製與更新,前提是有足夠的顯示記憶體可以讓資料載入,避免重複的從系統記憶體複製到顯示記憶體上的次數過於頻繁,在Maya的這樣的動畫軟體,透過GPU Cache的技術,就可以把繪製幾何的OpenGL資料直接放在GPU的記憶體中,並透過VBO(Vertex Buffer Object)的方式,直接映對記憶體位置繪製,配合新的Viewport 2.0的新drawing流程,給與硬體繪製幾何元件的最大效率。
但是事情總是沒有那麼的簡單,在GPU要把幾何資料繪製畫面上pixel前,還是必須要接受軟體所處理完的結果,像是幾何位移(translate)、旋轉(rotate)、矩陣轉換(matrix transformation)、變形(deformation)等等的計算。這個階段通常卡在Rigging的階段。一般來說,Rigging的部分使用到非常多的矩陣轉換與Transformation與Deformation的變動,這些變動通常結合關聯的節點Dependency Graph(contraint, deformer)或有階層式節點的Dag Node(joint, transform)做矩陣的轉換,加上IK Solver等等,通常是一串很複雜的求解的流程,這時候軟體其實最大的效率瓶頸就不是在繪製上面了,而是在每個節點相互求解時所花費的時間上,這個部分平行化較為困難,必須要考慮Node Graph哪些可以平行計算,哪些必須等待其他Node完成時才能計算,所以這些動作必須仰賴TBB Task Scheduler來做執行的排程與最佳的效率,這些動作的分配還是要透過CPU來處理,GPU只能在單一Node裡面幫忙計算的過程。在節點(Node)裡透過GPU時也不見得划算,因為GPU的資料要在系統記憶體裡不斷的複製資料到GPU的記憶體裡,才能開始做計算,而且資料無法在Node間共用,因此效率上也有待考慮。
像是FE(Fabric Engine)就提供了一種方法,把Maya的各個Rigging所需要的設定Node(像是 Joint, Skin Cluster, IK Solver)透過SpliceAPI開啟需要的輸入資料io Plug(像是Mesh, Transform等等),自家的KL語言來編寫Rigging的設定流程,包含所有Maya所使用的Deformer(SkinCluster, BlendShape, WrapDeformer…),最後使用SpliceAPI把結果透過FE直接用內部的OpenGL draw繪製出來,跳脫Maya標準的設定與Node結構,直接將KL編寫的Rigging設定程式碼,使用FE的LLVM動態最佳化編譯可供CPU或GPU執行Byte code,達到最佳的執行效率,而不會被Maya或Max這一類軟體內部標準的Node Evaluate機制所綁住。

Fabric Engine: Rigging Toolbox
任何運算要能在GPU上面跑,會跟演算法能不能夠有效率的在GPU的核心消化有關,不是任何在CPU上能跑的演算法都可在GPU上跑,像是一些物理引擎Bullet或PhysX,基本上都支援GPU,差別都是在可以有多少的幾何物件可以同時的計算,除了GPU的核心數之外,重要的就是記憶體的大小。像一般的Geforce遊戲卡本身所內建的記憶體量,通常以遊戲的需求來設計,大部分用來儲存幾合元件,貼圖與Render Target所需要的暫存,大約都在2~4G,跟以計算為目的的Tesla系列動輒6~12GB以上的記憶體,主要就是希望在計算中會有充足的記憶體來提供運算,避免重複交換大量的記憶體資料存取,而導致效能的低落。
在Fluid Dynamic的方面,Realflow早在2013年推出了以OpenCL為基礎開發的GPU加速,Maya的bifrost流體引擎因為使用自家的Compiler,透過開發者Marcus Nordenstam說,正在開發將編譯出來的可以在GPU上面執行的Code。
現在GPU在Rendering也有不少的應用,許多算圖引擎都使用GPU來做為加速的選項之一。現在比較相容於GPU的大致上就是Raytrace中的Path Tracing的陣營,也就是稱為Monte Carlo的方法,也就是說單純的Path Tracing是最適合使用GPU的運算,因為每條光線的路徑都是獨立的,在多核心架構的擴展上效率幾乎是線性的,但是Rendering所使用的各種Shader演算法與架構不盡相同,不一定都能在GPU上實現,所以在GPU上的Shader必須是統一的Shading Model,方便註冊單一的Core Function在GPU的核心做計算,以致於有一些算圖引擎移植到GPU上後Rendering的結果與CPU上的結果不太相同。貼圖在GPU上也因為記憶體的需求通常是個瓶頸,無法像CPU算圖時可以動態存取磁碟裡的貼圖或Swap,導致只要記憶體不足就會停住。GPU也可做為快速預覽Render燈光的計算,像是VRayRT主要目的是能幫助快速看到大致上算圖的結果。Nvidia就為了GPU Rendering做了一個Framework “OptiX”,Pixar與MPC使用這個framework配合物理的Shader,打造Realtime Lighting Preview的機制,也就是說GPU在Rendering的應用,都是做為加速製作流程為主,做為主要的算圖輔助。
Pixar GPU Lighting Preview at GTC 2014
MPC and NVidia Optix: Real-time Visualization for VFX
Mental Image所推出的Iray,底層使用的就是Nvidia的OptiX,目標就是完全使用GPU做為Render引擎,還有Octane Renderer,Furry Ball,Indigo Renderer等等,都開發的GPU的版本,不乏廠商看好這樣的趨勢投入GPU Renderer的開發。
還有一派使用GPU來做為算圖引擎的加速取樣,或在Rendering的某一個特定演算法提供GPU加速的機制,像是Mentalray或VRay等等,將GI演算法,移至GPU來做運算,現在的最大瓶頸也是卡在貼圖使用顯示卡記憶體的問題。
物理運算像是Rigid Body或是Soft Body現在也都可以在GPU上計算,Nvidia更推出了multi-physics solver的framework,提供以Particle-based的GPU多重物理解算器”FLEX”,

在新的CUDA規格裡也提到了新的Unified Memory,可以在統一存取系統與GPU記憶體,提升維護與複製記憶體資料的效率,還有程式開發的簡化,但是還是無法存取系統記憶體。對於Rendering部分的應用,實在是只能使用昂貴的GPU顯示卡來解決記憶體的瓶頸。
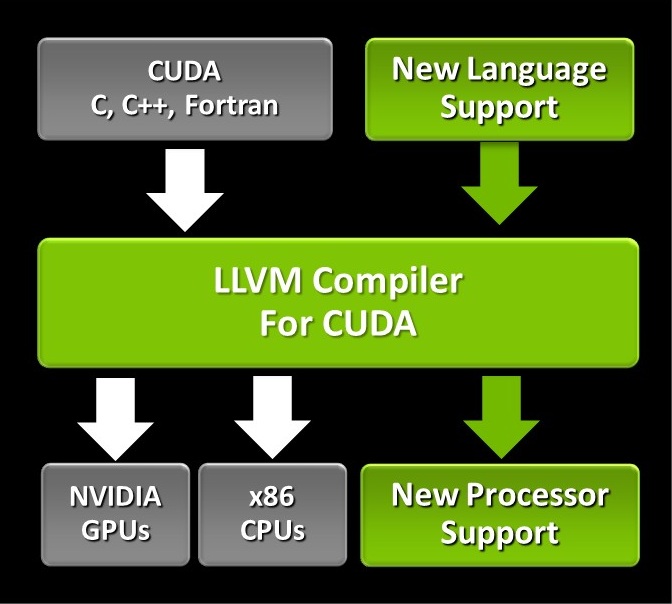
為了軟體應用的開發,也推出了以Nvidia CUDA LLVM的Compiler,透過這樣的技術,可以讓不同平台的CPU或GPU處理器,都可以使用編譯出來的中介程式碼,來減少程式的重複開發,並獲得程式碼最佳化優點。
由此可知,動畫界與特效界大致的走向差不多,重點是提升製作效率,使用GPU提升Rigging與Lighting的效率需要軟硬體架構的配合,還有一段的路要走,但是在物理運算的倒是可以加速不少,希望在不久的將來可以透過顯示卡記憶體的增加且價格平民化,來提升在動畫製作與特效的使用效率。